法規與監理
2025年7月
從工友到線上舞弊 內控難阻?
近來某銀行意外發現負責清潔、收寄信件等庶務工作的工友,竟利用收取分行承租戶水電費時,私吞兩百多萬元水電費的舞弊事件,足以顯示舞弊行為已不再是業務人員利用內控間隙舞弊;又迭次發生銀行員與詐騙集團勾結犯案情節,更顯部分銀行員在職業道德認知確實存有風險,影響及於犯罪與背信的社會問題。舞弊事件的發生,已不僅止於個別事件,更影響銀行企業社會責任與政府監理效能。因此,促請銀行將「與舞弊相關的特定風險」納入日間管理範疇,確實有燃眉之急的必要。
舞弊(Fraud)一詞,依國際內部稽核協會(IIA)發布之全球內部稽核準則定義:「指個人或組織為獲取不當或非法的個人或商業利益,而進行的以欺騙、隱瞞、不誠實、侵占資產或資訊、偽造或違反信任為特徵的故意行為」;又按審計準則公報第43號「查核財務報表對舞弊之考量」第6條指出:「所謂舞弊係指管理階層、治理單位或員工中之1人或1人以上,故意使用欺騙等方法以獲取不當或非法利益之行為⋯⋯。而所謂管理舞弊係指管理階層或治理單位成員中之1人或1人以上所涉入之舞弊行為,該項舞弊行為,可能僅為內部人員所為,亦可能是內部人員與外部第三人共同為之」。
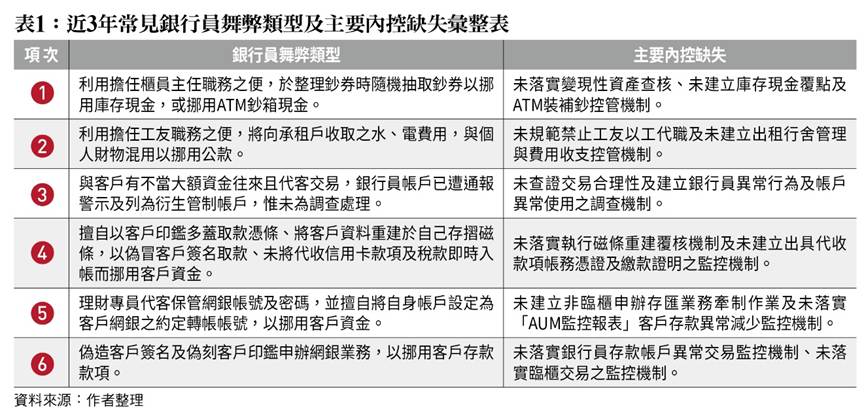
盤點近3年銀行常見銀行員舞弊類型及主要內控缺失,金管會對舞弊行為所衍生的內控問題,悉以違反銀行法第45條之1第1項及授權訂定「金融控股公司及銀行業內部控制及稽核制度實施辦法」第3條第1項、第8條第1項及第3項規定,爰依銀行法第129條第7款規定處予不等金額罰鍰,並促請確實辦理內控制度改善,惟類似舞弊情節卻仍持續發生(如表1)。
2025年4月間金管會預告「金融控股公司及銀行業內部控制及稽核制度實施辦法」修正草案(簡稱內控內稽辦法),參考國際內部稽核協會2020年發布《國際內部稽核協會三道防線模型:三道防線的更新版》,強調三道防線同步運作及相互協作的精神意涵,修正三道防線為三道防線模型,以落實三道防線之職能。此次修正更著重於自行查核、風險管理架構、風險導向內部稽核、責任地圖及法遵/風管/資安專責等制度的修正,藉此強化銀行各經營面向的內控效能。惟按近年斷斷續續發生的銀行員舞弊事件,不僅舞弊手法層出不窮,舞弊交易亦由實體線下交易轉為線上交易,更因勾串不法集團而致不法資金遭以虛擬資產交易隱匿,增加偵查難度,導致舞弊風險未見停歇或減弱。
舞弊事件雖屬個別事件,惟對以公益及信用為業的銀行而言,不僅造成客戶損害,對銀行商譽亦將遭折減,同時也影響民眾對主管機關監理效能的信任。此次修法雖大幅強化銀行內控制度效能,惟對舞弊風險之評估與監控規範是稍嫌不足,至於是否能達到防範舞弊事件發生,仍有討論空間。
國際內部稽核協會2024年發布的《全球內部稽核準則》,其中領域五「執行內部稽核服務」將舞弊風險明確納為內部稽核職責的重要範疇,而於指導原則十三中強調「內部稽核應考量與舞弊相關的特定風險」,並按原則十四「基於證據執行稽核」及原則十五「清楚、準確地傳達稽核發現與建議」。是以,對舞弊風險如能採行主動監控與納管,將有利於及早遏止舞弊事件之發生或減弱舞弊事件之影響程度。至於如何建立對舞弊事件的內部稽核制度,建議金管會除可另行規範銀行應將「與舞弊相關的特定風險」納入內部稽核範疇,並要求納入檢查計畫以為例行或專案查核項目,做好事前防範與事後及早發現,程度上仍可有效遏制舞弊風險的擴大。
至於內部稽核的執行,應可分3個層次:首先由作業流程評估舞弊風險的內控制度(如:授權、審核、分權制度),再進而針對高風險區域或業務種類執行深入測試、分析異常交易與趨勢(運用數據分析),最終與治理層溝通,要做到發現潛在舞弊徵兆時,能立即通報高階管理層或審計委員會,輔以內部稽核的平時監控,將能盡速確立舞弊人、事、物,以及時消弭或降低舞弊事件的發生與影響。(作者為台灣金融研究院副院長,曾任金管會檢查局銀行業務組組長)
