金融科技
2024年11月
資料無塵室或可解決兩者衝突
隱私與反壟斷規範的交鋒
這十年來,隱私監理機構一直要求網路平台減少分享使用者資訊。在這方面,歐盟的《一般資料保護規範》(GDPR)目前仍是黃金標準,世界各國與美國加州則陸續跟上。感謝GDPR的存在,隱私保護如今才能發展成一整個研究領域,目前已經可以詳細列出隱私外洩的危害。
但過去幾年,許多解決隱私問題的方法,加上美國在某些理念上的轉變,使得反壟斷對科技界的影響變得更大。在很多層面來說,反壟斷的立場與隱私保護完全相反:它要求科技平台不能把資料鎖在自己家,必須允許其他同業分享這些資料帶來的利益。這樣的要求,會對科技業者產生哪些影響?
兼顧隱私與反壟斷的關鍵要素,似乎不是法律,而是數學。去除個人隱私之後,資料能不能保留某些重要的洞見或結論?這個問題的答案,將影響消費者即將面對的網路未來,包括線上的金融服務。其中一個可能的解決方案稱為「資料無塵室」(Data Clean Rooms),也就是刪除資料中的個人資訊,再進行操作。
對抗性攻擊的資訊理論
隱私的核心問題是,歹徒在現實中有沒有可能還原個人資料。以重建攻擊(Reconstruction Attack)為例,歹徒找到一個已移除個人識別碼的資料庫,獲得每個未命名個體的特徵,然後再跟另一個儲存個人識別碼的資料庫結合起來,就可以得知每個人的完整個資(如表1)。
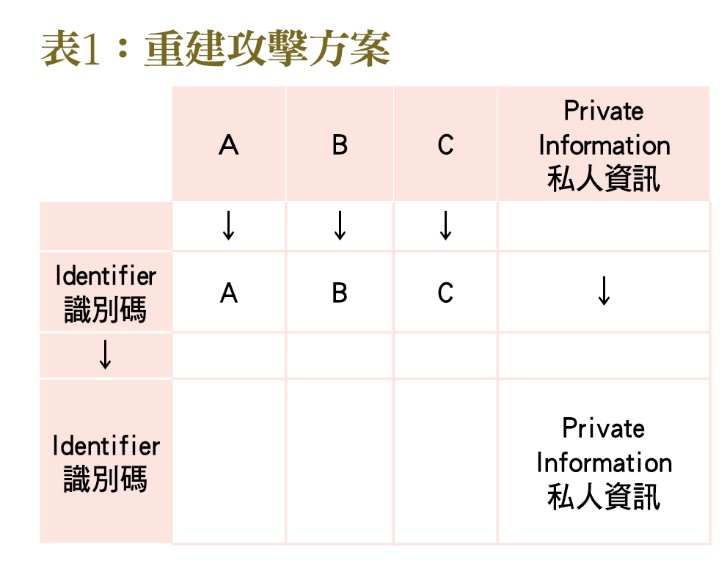
要防止重建攻擊,管理者就必須混淆特徵,讓每個人的個資難以直接連回識別碼,同時保留整個資料集的統計特徵,用來訓練因果推理或人工智慧。舉例來說,如果是金融交易的資料集,管理者可以在某個百分比範圍內調整金額參數,並將調整數值通知下游使用者。這時總體的平均數並不會改變,但如果這些方法未能奏效,重建攻擊就會成功。
真實世界的多變量資料,又比上述舉例複雜很多。許多攻擊都與創造力(Creativity)有關,攻擊者即使沒有直接存取到變數本身,依然可以利用變數裡面蘊含的資訊。所以資訊理論(Information Theory)把「資訊」定義得更廣,無論變數之間的交互作用,或者變數與現實世界的關係,都算是資訊。這就是差分隱私(Differential Privacy)背後的原理:利用資訊理論背後的數學,就能防止攻擊者從總體資料推算出個別資訊。
在背後的數學基礎下,差分隱私對隱私的解釋,與GDPR有所不同。一般來說,GDPR的「資料匿名」是指資料在混淆之後,完全刪除原始資料庫;如果沒有刪除原始資料庫,在使用混淆資料之前就依然必須獲得使用者許可。但差分隱私不管處理過的資料庫是否公開,甚至不管在使用資料時,原始資料庫是否存在。它對隱私的定義更符合人們私底下共享資料的狀況,畢竟你不太可能真的叫每個使用者完全刪除別人給過你的資料。
網路中心的谷歌
當代的許多隱私問題,都與開創廣告收入模式(Ad Revenue Model)的谷歌有關。谷歌的Chrome是最後一個允許第三方Cookie的主流瀏覽器,也是最容易被GDPR影響使用者體驗的對象。谷歌原本打算逐步淘汰第三方Cookie,卻在今年7月喊卡,顯然是因為衝擊了廣告生態系統。
谷歌多年來一直在開發一種名為Privacy Sandbox的方法,設法直接在使用者的瀏覽器上,運算前述的差分隱私。但來自Privacy Sandbox的資料,在市場上的價值卻降低了。這表示差分隱私內建的一個問題:它以加入雜訊的方式保護個人資訊,這些雜訊不會影響整體資料訓練出來的模型以及推導出的結論;但有可能降低了模型的最終性能或統計效用。
此外,監理機關也發現Privacy Sandbox竟然讓谷歌更能精細掌控使用者資料。英國競爭與市場管理局(Competition and Market Authority)懷疑Privacy Sandbox與招攬廣告的Google Ad Manager兩個工具之間互通有無。美國針對Google Ad Manager的反壟斷訴訟,截至9月中旬也還在繼續。檢方證人在訴訟中主張,購買廣告的人無法從谷歌那裡獲得「紀錄檔等級」(Loglevel data)的使用者足跡,無法獨立於谷歌之外,計算廣告投放的價值。如果這項訴訟成功要求谷歌將銷售與定價分離,個人資料的交易市場可能會成長得更快。
谷歌在審判之前聲稱,如果法院做出對其不利的判決,將「扼殺創新,提高廣告成本,使成千上萬小型企業和出版商更難發展」。沒有任何簡單的方法,能夠直接阻止重建資料,通常需要對現實世界的了解,以及技術和自動化技能的結合。
隱私可以成為價值主張
上述趨勢幾乎都與金融服務業無關。但隨著嵌入式金融(Embedded Finance)的崛起,金融機構也逐漸需要結合科技平台,而且可能需要讓消費者存取自己的金融資料。此外法律通常規定,最初因某目的而蒐集的資料,只要沒有經過使用者額外同意,之後就不能用於其他目的。許多金融機構都受限於這樣的規定,即使是同一公司的不同部門,也都不能共享資料。這顯示無論是資料生產者還是消費者,都需要某種方法,使其能夠安全地交換資料。
半導體產業有一種稱為「無塵室」(Clean Rooms)的無菌空間。目前某些雲端服務商,以及更專業的資料服務業者,都推出了同名的服務。這種服務通常並不便宜,但不會像Privacy Sandbox那樣遇到資料控管問題,而且可能成為繞過上述監理雷區的解方。
世界各地的監理框架,並非每個都像GDPR那麼嚴格;而且個人資訊類型繁多,並非每種資訊都同樣敏感。當然,隨著隱私威脅越來越複雜,重建攻擊之類的問題只會越來越多。許多社交工程(Social Engineering)的攻擊方式,都在利用「創造力」來入侵網路、進行詐欺。當你相信自己的敏感資訊安全地鎖在可信任的機構中,你就會把偷到那些敏感資訊的人全都當成可信任的機構。當這類攻擊逐漸自動化,瞎猜的成本低到趨近於零,就會跑出一大堆歹徒亂槍打鳥,用去除個人識別碼的資訊來釣魚。歹徒甚至還可以結合多個資料庫,提高瞎猜的正確率。
唯有解決這些問題,金融機構才能充分運用雲端運算與雲端儲存的潛力。當代人工智慧試圖盡可能地從每一個資料來源,蒐集最精細的資訊,整理成有用的結果。如果資料能夠集中在某個地方,人工智慧的整理通常就會更容易。當然,為了防止人工智慧侵犯隱私,在進行訓練之前,必須對資料進行充分保密。(本文作者為台灣金融研訓院特聘外籍研究員;譯者為劉維人)
