法規與監理
2024年4月
AI會誘發下一場系統性金融風險嗎?
ChatGPT橫空出世的省思:會泡沫化嗎?
2023年ChatGPT橫空出世後,帶來一波股市AI熱潮。然而各國金融監理機關卻不約而同的,陸續對AI可能危及系統性金融風險提出示警。這些擔憂可分為兩大類,第一類是AI演算法造成投資行為的「羊群效應」(Herding Behavior),加劇市場波動;另外是目前股市的AI概念股過熱,應注意避免重蹈當年的網路泡沫。
美國證券交易委員會(SEC)主席Gary Gensler在2021年就職,之前他是麻省理工學院的教授,並曾在2020年發表《深度學習與金融穩定》論文,指出AI的發展與運用對金融穩定的威脅。例如使用AI作為投資決策工具時,由於這些演算法使用相同的模式來訓練,因此會發生「學徒效應」(Apprentice Effect),造成大家同步買、同步賣的現象。再加上目前高頻交易的盛行,將推升市場「閃崩」(Flash Crashes)的風險。同樣的,金融監理機關若是以AI來作為監理輔助工具,也會造成監理偏差,影響投資行為。Gary Gensler在2023年7月的一場公開演講中再次闡述這個風險,並認為AI可能造成下一場的大型系統性金融風險(Next Big Systemic Risk)。
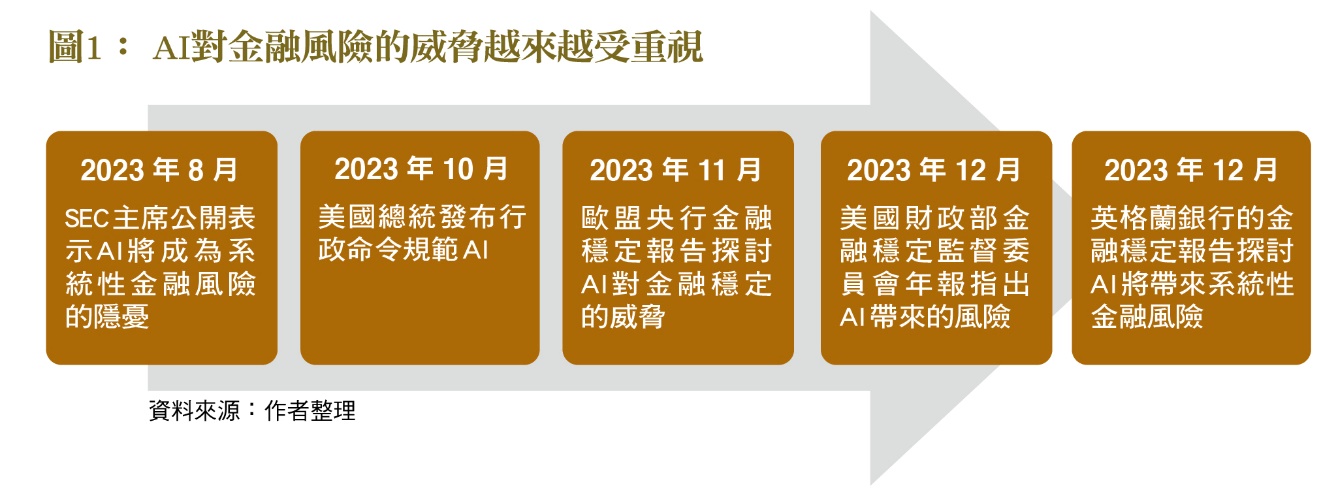
葉倫首次將AI列為影響金融風險因素
2023年12月美國財政部在公布《金融穩定監督委員會年報》(Financial Stability Oversight Council Annual Report)時,財政部長葉倫的發言除了針對當前最受矚目的通膨與烏俄戰爭議題之外,特別指出AI對金融穩定的影響。她指出,AI工具往往非常技術性與不透明,不容易解釋,也不容易監測其缺點。假如金融業或監理機關對AI不夠了解,那就很可能造成偏差或不正確的結果。並且AI往往依賴大量的外部資料庫,或是第三方供應商,也加深個資保護與資安風險的疑慮。當天SEC主席Gary Gensler也出席該發表會,重申他之前的看法。由於美國各界對此均有共識,因此2023年10月美國總統發布行政命令來規範AI的使用﹝圖2﹞,以達到安全、信任的使用AI技術,降低風險。
事實上,在大西洋彼岸的歐盟央行也有相同關切,如2023年12月英格蘭銀行發布的金融穩定報告,也提到AI與機器學習可能誘發英國金融穩定的疑慮。雖然過去十幾年來,AI與機器學習技術廣泛被運到反洗錢與防詐,但近來由於相關技術的發展以及計算成本的降低,使得運用層面更廣,此議題也更不容忽視。雖然個別企業使用AI技術所造成的風險相對很低,但假如廣泛被使用後就容易出現系統性金融風險的問題。因為即使每個金融機構用AI做很小的決定,但因「從眾效果」(Herding Effect)就可能造成傾斜。由於很少人了解AI是如何運作,使得金融監理機關不易要求業者如何「負責任」的使用AI技術。但業者若不了解AI如何運作,卻廣泛使用高頻交易與高運算技術,在瞬間進行大量交易的風險可想而知。
ECB憂心 AI概念股飆漲造成泡沫化
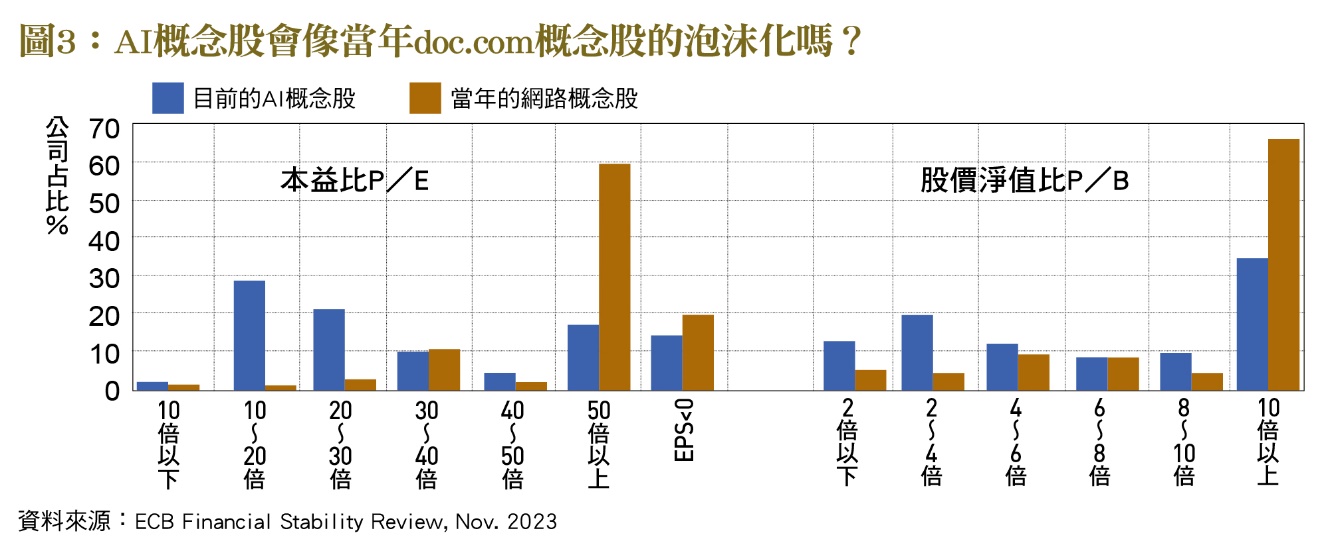
歐盟央行(ECB)在2023年11月的金融穩定報告中,對AI的擔心則有兩方面。包括AI與金融服務數位化發展將放大與加速金融穩定風險,特別是交易工具App的盛行與便捷,再加上社群媒體推波助瀾的效果,都將加大市場不合理的波動。另外,歐盟央行還擔心,股市所謂的AI概念股飆漲,將造成資產泡沫化的疑慮,還比較這些AI概念股的本益比與當年網路泡沫化高峰時的達康概念股。雖然在歐盟的AI概念股並不像在美國掛牌的那些公司,有過熱的疑慮,但歐盟央行還是擔心美國股市資產泡沫化之後,對歐洲股市的外溢衝擊。
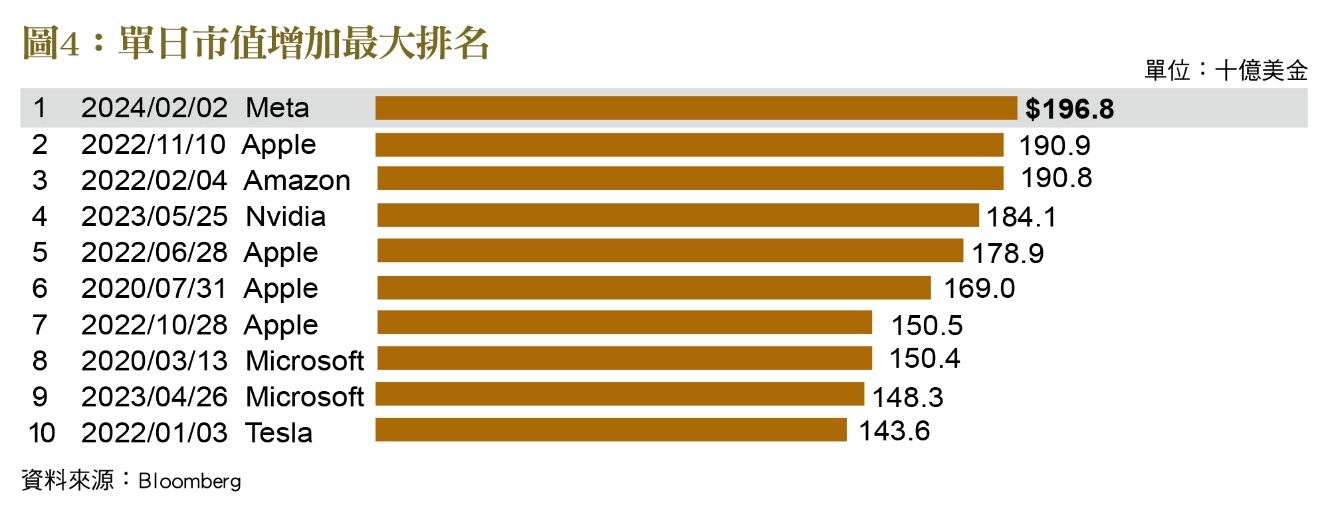
從歐盟央行所整理的﹝圖3﹞可知,當年網路泡沫最高峰時,有6成的網路公司本益比在50倍以上,而目前AI概念股則還不到2成。當年有高達6成的網路公司股價淨值比超過10倍以上,目前則還不到4成的公司。雖然目前AI概念股的泡沫化程度還不若當年網路概念股,但其股價處於高檔卻是不爭的事實,再加上目前各界普遍預期今年聯準會會降息,更是為部分投資者壯膽不少,也加深資產泡沫化的疑慮。今年2月AI概念股Meta市值單日增加將近2,000億美元,創下歷史紀錄,其他Apple、Amazon、Nvidia跟Microsoft之飆漲也都與AI有關﹝圖4﹞。這些AI概念股不畏升息與地緣政治緊張等利空消息持續飆漲,熱錢氾濫無處去應該是主要原因之一。(本文作者為台灣金融研訓院金融研究所資深研究員)